Features Overview
This section gives a quick overview of the Open Discover® SDK API document file format identification and extracted document content features.
This topic contains the following sections:
Document File Format Identification
Open Discover SDK allows users to reliably identify document file formats using unique internal file signatures of the various supported document formats. Currently, over 1,600 file formats are supported for identification. See Id enumeration for the supported file format identifications.
To identify file formats, developers use the overloaded SDK method DocumentIdentifier.Identify. This method returns a IdResult object with properties that contain useful information on the identified file format, such as:
| ID | Contains the identified file format as a Id enumeration value, e.g., Id.OutlookMessage, Id.OutlookMeetingRequestAccept, Id.Excel2007Template, Id.OutlookPSTUnicode, etc. |
| Classification | Contains the classification of the file format as a IdClassification enumeration value. This property can be used in full-text search indexes as indexable/searchable fields to help filter search results by document classification, for example, to limit a search to all IdCassification.WordProcessing document formats or to limit a search to all IdCassification.Spreadsheet document formats. |
| EncodingID | For text-based formats this property holds the detected text encoding (specified by an Id enumeration value) of the text based format, e.g., Id.Text7BitASCII, Id.Text_Shift_JIS, Id.Text_Big5, Id.Text_Windows_1250, Id.TextUTF8, etc. |
| MatchType | Gives information on quality (confidence) of the file format identification. |
| MediaType | If known, the IANA Media Type (formerly known as MIME Type) of the file format. |
| Description | A string description of the file format. |
| Extensions | A string of all known file extensions associated with this file format. |
| And more, see IdResult |
To see how to programmatically identify document file formats using the DocumentIdentifier class see the Identify Document File Formats help topic.
Extract Document Content: Text, Metadata, Attachments, and more...
This section contains the following subsections:
- DocumentContent Class
- EmailDocumentContent Class
- HtmlDocumentContent Class
- ArchiveContent Class
- MailStoreContent Class
- DatabaseContent Class
Open Discover SDK for .NET allows users to extract various document content from documents using a factory pattern. The sub-sections that follow give a brief description of the types of content extracted for office documents, images, multimedia, emails, PDFs, HTML, archive containers, mail store containers, and database files. In addition to extracting archive and mail store container level metadata, the SDK also supports extracting items from archive (7ZIP, ZIP, RAR, TAR, etc) and mail store (PST, OST, MBOX, etc) containers.
Open Discover SDK can extract over 1,350+ known metadata fields across all supported file formats. See OpenDiscoverSDK.Interfaces.Metadata namespace for known metadata fields and helper classes.
The sub-sections that follow briefly describe the types of document content (i.e., "what data can you extract") that are extracted from document formats and not the "how to" in getting the content. To see how to programmatically extract document content and how to extract items from archive and mail store containers using the ContentExtractorFactory class see the "How To" Extract Content using the SDK ContentExtractorFactory help topic.
DocumentContent Class
The DocumentContent class stores the following extracted document content:
| ExtractedText | Document text (including user comments and optionally revision tracking text) |
| Metadata | Standard (non-user-defined) document metadata |
| CustomMetadata | User defined document metadata |
| Attributes | DocumentAttributes are used to alert end user of password protected documents, externally linked content, special content, and more... |
| HyperLinks | Hyperlinks extracted from HTML, PDF, and supported office formats |
| ChildDocuments | Attachments/Embedded objects and office media |
| MD5BinaryHash | SHA-1 binary hash (hash of all document bytes) |
| MD5ContentHash | Proprietary content-based MD5 hash for supported email and office document formats |
| SHA1BinaryHash | SHA-1 binary hash (hash of all document bytes) |
| SHA1ContentHash | Proprietary content-based SHA1 hash for supported email and office document formats |
| LanguageIdResults | Languages identified in extracted text |
| EntityExtractionResult | Detection of sensitive items such as social security numbers, credit card numbers, health insurance member IDs, driver's license numbers, social media accounts, and more. See EntityType. In addition to sensitive item information, the SDK will also return information on recognized entities related to person name, banking, hospitals, legal, health care, insurance, and more. See Entity. |
| And more, see DocumentContent for more information. |
Document hashes, e.g., SHA1BinaryHash and SHA1ContentHash, can be used to identify exact binary (bit-wise) duplicate documents or identify documents with same content (same text and attachments). In addition to SHA-1, MD5 binary and content hashes (see MD5BinaryHash and MD5ContentHash) are calculated because of their legacy in electronic discovery (eDiscovery) industry.
The DocumentContent class stores the extracted content for all document formats except for the following derived special content classes that store additional extracted content:
- Emails (see EmailDocumentContent)
- PDF documents (see PdfDocumentContent)
- HTML documents (see HtmlDocumentContent)
- Archive/media image containers (7Z, ZIP, RAR, TAR, WIM, etc) (see ArchiveContent)
- Mail store containers (PST, OST, MBOX, etc) (see MailStoreContent)
- Database files (see DatabaseContent)
Each of the above special DocumentContent derived classes are discussed in sections below. A class diagram of the DocumentContent derived classes:

EmailDocumentContent Class
The EmailDocumentContent class stores the content from its DocumentContent base class as described above but also has the following additional extracted email specific content:
| AttachmentNames | Normalized list of attachment names separated by "; ". |
| BccRecipients | "Bcc" recipient email information. |
| Body | The email text body used for the extracted email text. |
| BodyType | The email body format used for the extracted email text. |
| CcRecipients | "Cc" recipient email information. |
| CreationDate | Email creation time. |
| EnrichedBody | If property HasFlowedBody is true, then this property contains the Enriched formatted body. |
| EntryId | Entry ID for Outlook PST/OST extracted message objects in hexadecimal string format. |
| FlowedBody | If property HasFlowedBody is true, then this property contains the Flowed formatted body. |
| From | Specifies the author(s) of the message |
| HasEnrichedBody | True if this email has a Enriched formatted body. |
| HasFlowedBody | True if this email has a Flowed formatted body. |
| HasHtmlBody | True if this email has an HTML body. |
| HasRtfBody | True if this email has an RTF body. |
| HasTextBody | True if this email has a plain-text body. |
| HtmlBody | If HasHtmlBody is true, then this property contains the HTML body. |
| InReplyToId | MIME 'in-reply-to' header value (if it exists). Contains the value of the original message's MessageId property. |
| IsMimePartialMessage | True if this is an MIME email partial message (ContentType MIME header with MIME-type = "message/partial"); false otherwise. |
| LastModificationDate | Email's last modified time. Check property DateTime.Kind value to determine if UTC, Local, or Unspecified time. |
| MessageId | MIME 'message-id' header value (if it exists). This is also set for Outlook .msg files, if it exists. |
| MimePartialMessageId | If IsMimePartialMessage property is true, then property holds the unique partial message 'id'. |
| MimePartialMessagePartNumber | If IsMimePartialMessage property is true, then property holds the index of this message part (valid range: 1 to MimePartialMessageTotalParts). |
| MimePartialMessageTotalParts | If IsMimePartialMessage property is true, then property holds the total number of MIME partial-message parts. |
| RtfBody | If HasRtfBody property is true, then this property contains the Rich Text Format (RTF) body. |
| RtfHasEncapsulatedHtml | If true, the RTF email body (see property RtfBody) has encapsulated HTML (from Microsoft Outlook conversion to RTF); false otherwise. |
| Sender | Email sender information. The sender is the EmailAddress of the agent responsible for the actual transmission of the message. |
| SentDate | Email sent time. Check property DateTime.Kind to determine if UTC, Local, or Unspecified time. |
| SHA1AttachmentHash | SHA-1 hash of the concatenated SHA1 hash of each attachment binary data (includes hashes of inline images). |
| SHA1BodyHash | SHA-1 hash of the email Body property text (converted to lower case and with all white space removed). |
| SHA1HeaderHash | SHA-1 hash of concatenated message SentDate property date (e.g., Microsoft Outlook (.msg)'ClientSubmitTime' or MIME 'Date' field), subject, Sender property name and email address (converted to all lower case and all white space removed before hashing). |
| SHA1RecipientNamesHash | SHA-1 hash of all recipient names concatenated together (all lower case). |
| SHA1RecipientsHash | SHA-1 hash of all recipient names and email addresses concatenated together (all lower case). |
| Subject | Email subject text. |
| TextBody | If HasTextBody property is true, then this property contains the plain-text body. |
| ToRecipients | "To" recipient email information. |
In addition to the above properties, the base class DocumentContent.Metadata dictionary property contains many useful email specific metadata fields extracted from email objects. The best way to get a feel for all the content extracted from supported email formats is to run the following Github SDK content extraction example C# application on email formats: Open Discover® SDK ContentExtraction Example
Example screen shots of the Open Discover® SDK ContentExtraction Example application that displays the extracted content of one of the test emails in the Github repository's "TestFiles\Email" folder:
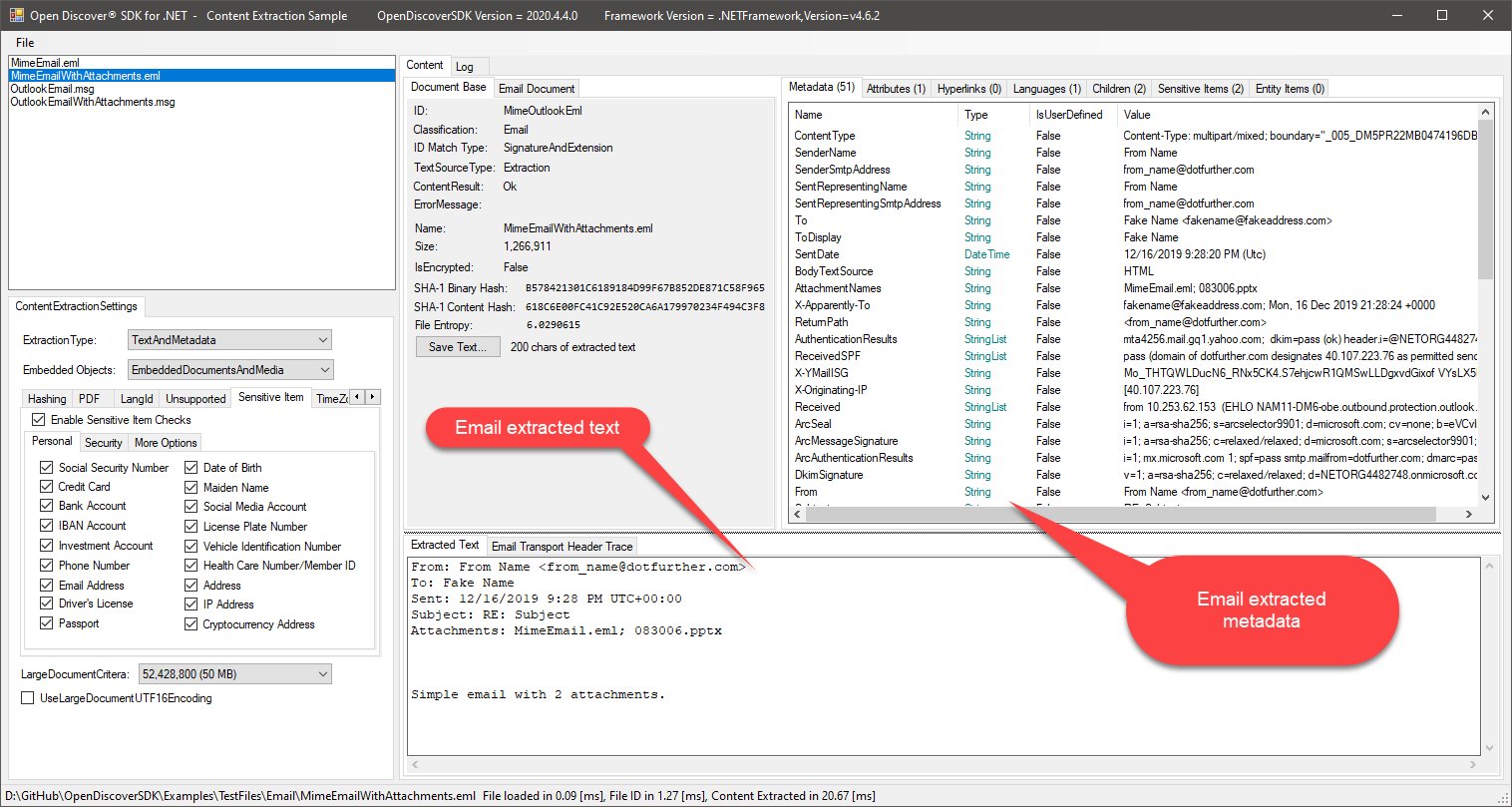
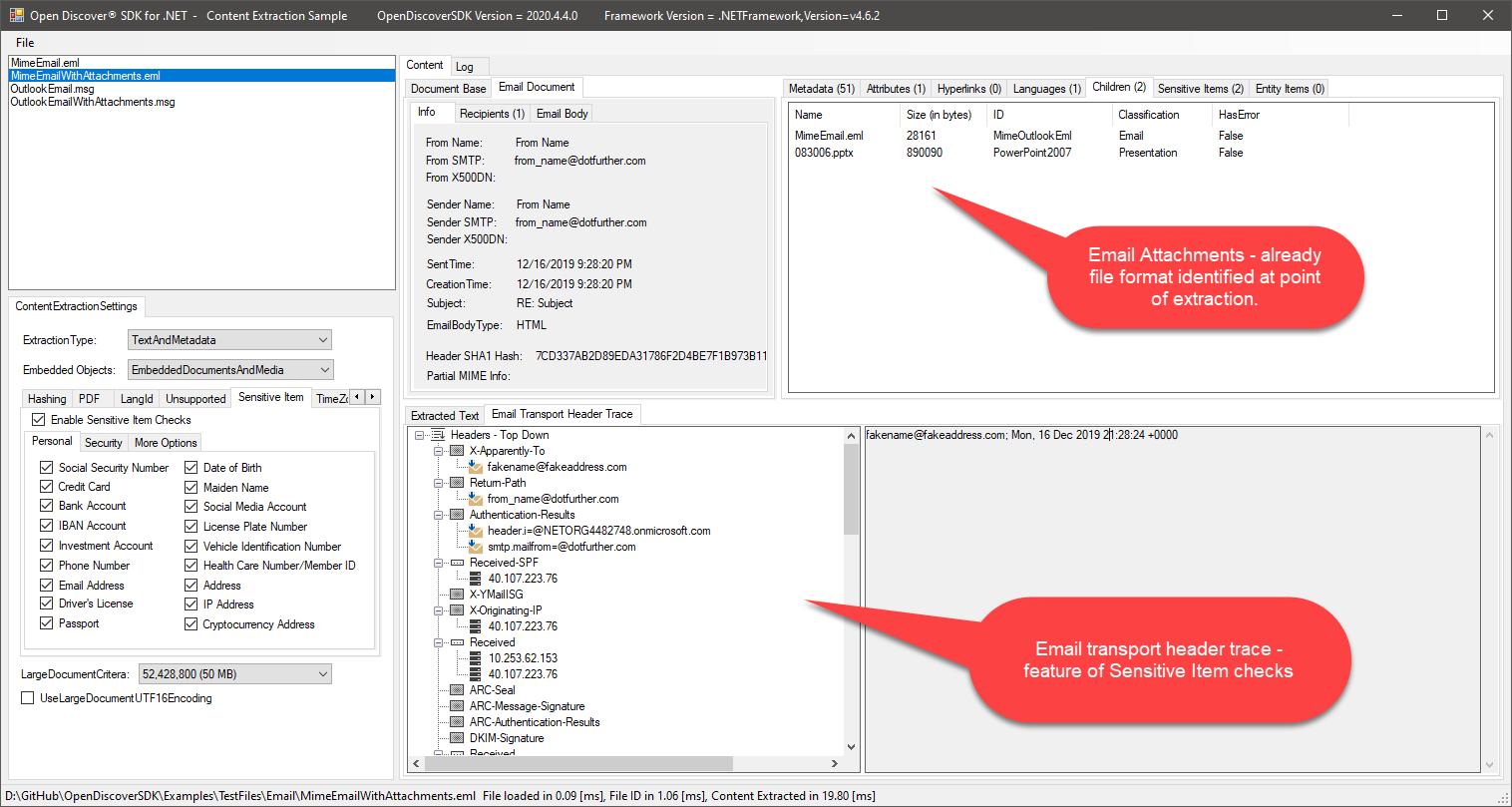
The MD5ContentHash and SHA1ContentHash are especially useful for finding duplicate emails in a document set that were saved in the same or different email client formats.
HtmlDocumentContent Class
The HtmlDocumentContent class stores the content from its DocumentContent base class as described above but also has the following additional extracted HTML specific content:
| BaseTarget | The HTML "base" element tag specifies the base URL/target for all relative URLs in a HTML document. |
| BaseUrl | The HTML "base" element tag specifies the base URL/target for all relative URLs in a HTML document. |
| ImageTags | HTML 'img' tag information. |
| Title | The HTML "title" element text. This value is null if not defined in document. |
Any HTML hyperlinks extracted are stored in the inherited base class HyperLinks property.
ArchiveContent Class
The ArchiveContent class stores the following extracted archive/media image content:
| HasEncryptedItems | True if any archive items are password protected (encrypted). |
| ItemCount | The total archive item count. This count includes only file items and not any directory items. |
| Root | Archive internal directory (folders) structure (if it exists). The root ContainerFolder is the root directory folder which all sub-directory folders are listed. |
The ArchiveContent.Root property contains the archive's internal directory hierarchy, if the specific archive format supports directories and if internal directories exists.
Information on archive items is stored in the inherited base class property ChildDocuments; however, unlike office documents, emails, and other regular documents, the ChildDocument objects that correspond to the archive items do not have their FormatId property set nor their DocumentBytes property because at this point they have yet to be extracted. Note, the user has to programmatically extract each child item in order to get at the item data (file bytes).
How to extract an archive container's items is discussed in the "How To" section. The best way to get a feel for all the content extracted from supported archive/media image formats is to run the following Github SDK content extraction example C# application on archive formats: Open Discover® SDK ContentExtraction Example Open Discover® SDK ContentExtraction Example
MailStoreContent Class
The MailStoreContent class stores the following extracted archive content:
| MessageCount | |
| Root | Mailstore root folder (only defined for mail containers that have internal folder structures. Not set for MBOX mail stores). The root ContainerFolder is the root directory folder which all sub-directory folders are listed (if they exist in mail store container). |
The MailStoreContent.Root property contains the mail store container's internal directory hierarchy, if the specific mail store format supports directories and if internal directories exists.
How to extract a mail store container's email objects is discussed in the "How To" section. The best way to get a feel for all the content extracted from supported mail store formats is to run the following Github SDK content extraction example C# application on archive formats: Open Discover® SDK ContentExtraction Example Open Discover® SDK ContentExtraction Example
DatabaseContent Class
The DatabaseContent class stores the following extracted archive content:
| Tables | Database table and corresponding table column metadata. |
How to extract a database's table text and any binary table column objects is discussed in the "How To" section.