Extract Content using the SDK ContentExtractorFactory
This topic and sub-topics show how to use the Open Discover SDK content extractor factory pattern to extract content from documents and items from archives and mail store containers.
The steps to extract document content or to extract items from archive or mail store containers:
- Identify the document's file format using one of the overloaded DocumentIdentifier.Identify methods.
- Use method ContentExtractorFactory.GetContentExtractor to get an ContentExtractorResult object for the specific file format identified in step (1) above.
- Use the ContentExtractor property of the returned ContentExtractorResult object in step (2) above to get the base IContentExtractor extractor interface.
- Use the IContentExtractor object's ContentExtractorType property to determine the type of the IContentExtractor derived interface that is specific to extracting content for the file format.
- Type-cast the base IContentExtractor interface to the specific derived IContentExtractor interface and use that interface to extract the desired content.
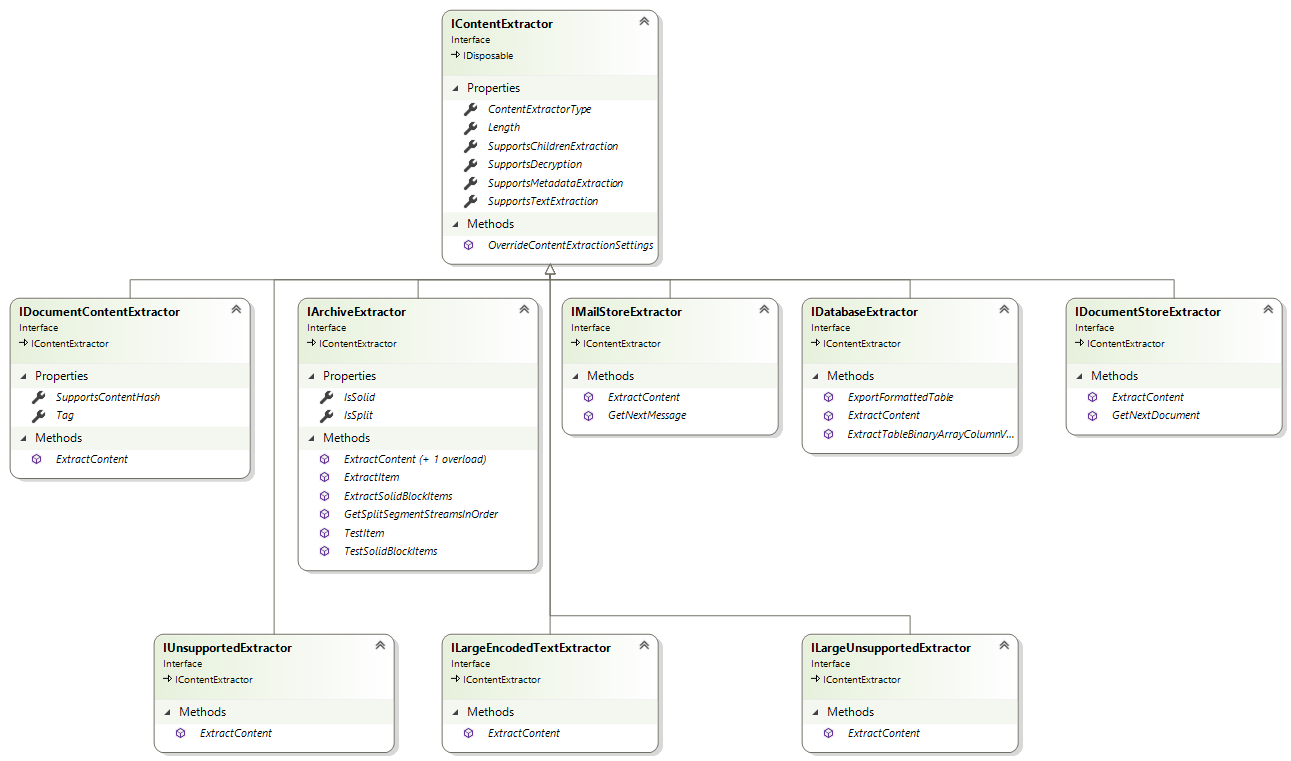
The following are all of the IContentExtractor derived interfaces:
- IDocumentContentExtractor - returned for supported non-container documents such as office documents, emails, PDFs, HTML, XML, multimedia, raster images, vector images, etc.
- IArchiveExtractor - returned for supported archive container types such as 7ZIP, ZIP, RAR, TAR, GZIP, etc.
- IMailStoreExtractor - returned for supported mail store container types such as PST, OST, MBOX, etc.
- IDatabaseExtractor - returned for supported database file types, currently only Microsoft Access database is supported by this interface.
- IDocumentStoreExtractor - returned for supported document store container types, currently only Domino DXL document database export file (an XML database of documents) is supported by this interface.
- IUnsupportedExtractor - returned for unsupported document formats if UnsupportedFiltering is true. This interface allows for binary-to-text filtering on unsupported formats.
- ILargeUnsupportedExtractor - returned for "large" unsupported document formats. "Large" is defined by property LargeDocumentCritera. This interface allows for binary-text filtering of very large files but writes the filtered text (which can be very large) to a System.IO.FileStream object instead setting the ExtractedText property (in-memory string) with extracted text. See also UnsupportedFiltering.
- ILargeEncodedTextExtractor - returned for "large" encoded text documents (e.g., large CSV formatted files). "Large" is defined by property LargeDocumentCritera. This interface is only useful if encoded text file is not in an easily indexed encoding like UTF-8 or UTF-16. The extracted text, which is written to a System.IO.FileStream object instead of setting the ExtractedText property (in-memory string), is automatically written in UTF-8 or UTF-16 encodings. See property UseLargeDocumentUTF16Encoding.
Diagram of the IContentExtractor derived interfaces:
The following example shows the pattern of how to get the specific IContentExtractor derived interfaces. How to use the specific derived interfaces is discussed in this section's sub-topics.
Document Content Extraction Pattern
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91
var settings = new ContentExtractionSettings();
settings.CalculateBinaryHash = true; // Calculate binary hashes
settings.CalculateContentHash = true; // Calculate content hashes on supported formats such as emails and Office documents
settings.ExtractEmbeddedDocuments = true; // Extract attachments\embedded documents
settings.ExtractOfficeEmbeddedMedia = true; // Extract embedded media for Office formats
settings.ExtractionType = ContentExtractionType.TextAndMetadata; // We want text and metadata extracted
using (var stream = File.OpenRead(filePath))
{
//========================================================================================
// Step 1 - Identify document file format:
//========================================================================================
var docIdResult = DocumentIdentifier.Identify(stream, filePath);
//========================================================================================
// Step 2 - Get the content extractor result for the file format:
//========================================================================================
var contentExtractorResult = ContentExtractorFactory.GetContentExtractor(stream, docIdResult, filePath, settings);
if (contentExtractorResult.HasError)
{
LogErrorMessage(string.Format("Error getting content extractor for file ID {0}: {1}", docIdResult.ID, contentExtractorResult.Error));
}
else
{
//========================================================================================
// Step 3 - Get the specific IContentExtractor derived interface for the file format:
//========================================================================================
var extractorType = contentExtractorResult.ContentExtractor.ContentExtractorType;
switch (extractorType)
{
case ContentExtractorType.Archive:
{
var archiveExtractor = (IArchiveExtractor)contentExtractorResult.ContentExtractor;
// TODO: Following help topics will show how to use this interface
}
break;
case ContentExtractorType.Document:
{
var docExtractor = ((IDocumentContentExtractor)contentExtractorResult.ContentExtractor);
// TODO: Following help topics will show how to use this interface
}
break;
case ContentExtractorType.MailStore:
{
var mailStoreExtractor = ((IMailStoreExtractor)contentExtractorResult.ContentExtractor);
// TODO: Following help topics will show how to use this interface
}
break;
case ContentExtractorType.Database:
{
var databaseExtractor = ((IDatabaseExtractor)contentExtractorResult.ContentExtractor);
// TODO: Following help topics will show how to use this interface
}
break;
case ContentExtractorType.DocumentStore:
{
var docStoreExtractor = ((IDocumentStoreExtractor)contentExtractorResult.ContentExtractor);
// TODO: Following help topics will show how to use this interface
}
break;
case ContentExtractorType.Unsupported:
{
// Binary-to-text extraction: Note, if property ContentExtractionSettings.BinaryToTextOnUnsupportedTypes is false, then calling
// IUnsupportedExtractor.ExtractContent will only calculate binary hashes without performing binary-to-text filtering.
// Binary-to-text is not useful for file formats (e.g., Id.MPEG1ElementaryStream) that do not have any textual
// content. It is up to the user to filter these formats out using either file format Id or file format classification.
var bin2TextExtractor = ((IUnsupportedExtractor)contentExtractorResult.ContentExtractor);
// TODO: Following help topics will show how to use this interface
}
break;
case ContentExtractorType.LargeUnsupported:
{
// Binary-to-text extraction - we extract to a memory stream here but user should extract to a file stream for the cases
// of very 'large' binary documents - because the filtered text could get into the gigabytes
// depending on the BLOB size and content.
var largeDocBin2TextExtractor = ((ILargeUnsupportedExtractor)contentExtractorResult.ContentExtractor);
// TODO: Following help topics will show how to use this interface
}
break;
case ContentExtractorType.LargeEncodedText:
{
// "large" encoded text file extraction
var largeEncodedTextExtractor = ((ILargeEncodedTextExtractor)contentExtractorResult.ContentExtractor);
// TODO: Following help topics will show how to use this interface
}
break;
}
}
}